![]()
- 2019/01/09(水)、渋谷で行われたCloud Native Meetup Tokyo #6 KubeCon + CNCon Recap – connpass への参加レポート。
- ハッシュタグ #cloudnativejp
- 転職しちゃったIさんとNさんに再会できてうれしかった。お酒ごちそうさまでした。
Cortex の話をKubeConで聞きたかった話
- Shinya Uemura @uesyn (KDDI & Creationline)
- Cortexの話をKubeConで聞きたかったっていう話 – Speaker Deck
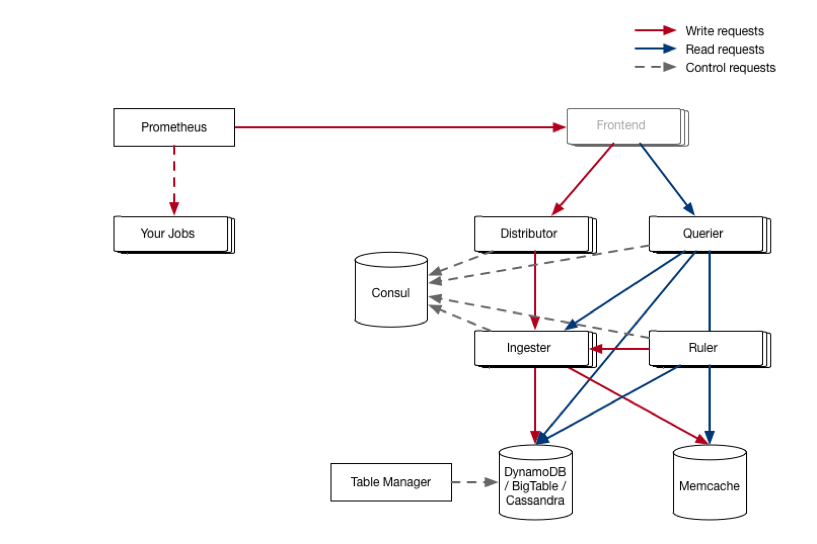
- PrometheusのローカルストレージはLong-term Storageではない
- レプリケーション機能がなかったりやクラスター化されていない
- Cortex
- Prometheusのメトリクスの長期保管のためのストレージ
- Frontend
- Cortexに含まれていないため、自分で実装する必要がある
- Distributor
- Prometheusから送信された時系列データを処理する
- 複数のIngesterに並列でサンプルを送信する
- 分散ハッシュテーブルを活用
- コンシステントハッシュテーブル
- ステートレスな設計
- Ingester
- 時系列データを長期ストレージバックエンドへ書き込む
- 数時間分のデータを圧縮し、チャンクとしてバックエンドストレージへ保管
- 過去12時間のデータを保持しておく
- 時系列データを長期ストレージバックエンドへ書き込む
- Chunk store
- 2種類のデータストア
- Chunkとしてまとめられた時系列データを保存
- Chunkのための転置インデックスを保存
- 2種類のデータストア
- Query Frontend
- テナントからのReadリクエストをいい感じにQuerierに流してくれる
- テナントごとのキューイングなど
- オプションのサービスなので省略可能
- テナントからのReadリクエストをいい感じにQuerierに流してくれる
- Querier
- クライアントからのPromQLクエリを処理
- 取得する時系列データへのアクセスの抽象化
- Ruler
- Alertingのためのルールを実行してアラートをAlert managerに送信
- CortexのインストールにはAlertmanagerも含まれる
マルチテナント対応
- リクエストに含まれるヘッダ内のIDでテナントを判断
- テナントIDごとにPrometheusのメトリクスを分割して保存可能
- Cortex自体に認証認可の機能は含まれず、実装が必要
- Headerに埋め込むテナントID: X-Scope-OrgIDで識別
Cortexをk8s上で動かそう
- つらい
- リリースブランチがない、タグもない
- Masterから…
- 公式の入門ドキュメントがない
- For Developerに記載されたとおりに動かしても動かない
- Frontendの実装が必要
手順
- make
- k8sディレクトリ内のマニフェストのimageを上記へ置換
- 一部マニフェスト内のargumentが間違っている部分を修正
kubectl create -f ./k8skubectl port-forward svc/nginx 9999:80curl http://127.0.0.1:9999/api/prom/api/v1/query?query=up
まとめと今後
- まとめ
- cortexの歴史と概要
- 取りあえず動く手順
- 今後
- 本物のDynamoDB、S3への接続
- 負荷テスト
- Ruler, table-manager, schemaの調査
- 似たような設計のLokiの調査
KubeCon + CNConに見るetcdの未来
- Akihiro Ikezoe @zoetro (Cybozu)
- CybozuはVMからコンテナへどんどん移行中
- KubeCon+CNConに見るetcdの未来 – Speaker Deck

etcd
- 現Red hat社 (旧CoreOS社) が華髪する分散キーバリューストア
- High Available
- Strong Consistency Model
- Raftによる分散合意
- Transaction, Watch, Lease
etcdの未来
- CoreOSがRed Hatに買収され、Red HatもIBMに買収される予定
- Container Linux: Fedora CoreOSが後継
- etcdがCNCFプロジェクトに
- Red Hat社からCNCFへ寄贈
- もともと開発者は外部が多かったので開発体制に大きな変化はなさそう
- 今後は使いやすさや安定性、性能の向上
新機能
- Raft Learner
- Raft: etcdの分散合意アルゴリズム
- ネットワーク分断などの障害が発生しても、データの不整合を発生させないことを保証する
- 現状の問題点
- クラスタに新しいメンバを追加したときに、データ同期に時間がかかる
- データ同期中はI/O負荷が高い
- データ同期中にネットワーク分断が発生すると、クラスタ崩壊が発生する
- 起動パラメータをミスっていると、故障したメンバーがクラスタへ追加されてしまう
- Raft Learner
- データ同期中はLearner状態に
- Raft: etcdの分散合意アルゴリズム
- Cluster init
- etcdは起動オプションがたくさんある (リッスンするアドレスやメンバーごとに名前など)
etcdadm
- etcdの運用は大変
- HA構成、証明書管理、クラスタが崩壊しないようにメンバを追加。削除
- 運用を自動化するツールが必要となる: etcdadm
- 実機やVM向けのetcdクラスタ運用自動化ツール
- k8s向けに特化
- メンバーの追加削除
- バックアップとリストア (DR)
- アップグレード・ダウングレード
- 証明書の管理
トラブルシューティング
- デバッグのアプローチ
- etcd起動確認
- ディスクスペースが空いているか?
- リクエストに時間がかかっていないか?
- ツール
- etcdctl
- auger
- etcd-dump-logs
QA形式のセッション: Deep Dive
- なぜデータサイズに制限があるのか?
- デフォルトで2GBの制限がある
- データベースファイルをmmapするため、データ量分のメモリが必要
- なぜコンパクションが必要なのか?
- キーごとの履歴を保持している
- 古い履歴を削除しないと、データ容量が増えリストア時間も憎愛する
- なぜI/Oレイテンシに敏感なのか
- 定期的にリーダーからフォロワーにハートビートを送信して、分散合意のメタデータをファイルに保存している
- ファイル書き込みが遅いとハートビートがタイム・アウトする
- できるだけSSDを使うべき
まとめ
- etcdはk8sを始めいろいろなところで使われていてなくてはならない存在
- CNCFに加わったことで今後のメンテナンスは安心感
- 運用者向けの新機能が多数
Monitoring Kubernetes Audit Log by Falco
- Makoto Hasegawa @makocchi (CyberAgent)
- kubecon2018_recap_falco_deep_dive – Speaker Deck

Falco
- Container Native Runtime Security
- コンテナ環境のセキュリティをモニタリングしてくれるOSS
- 主にsysdigが開発
- モニタリングをするだけで一切に処理をブロックしたりすることはない
仕組み
- Falco Rules
- Falco Engine
Kernel module / sysdig libraries
Falcoを実行するとDKMSによってmoduleがbuild&installされる
lsmod | grep falco- Rule をyamlで記述することでモニタリングするイベントを定義する
Notify
- Falcoには検知した際にプログラムを実行する仕組みがある
- 外部へのWebhookとか可能 (Slack連携)
falco.yamlの設定- Kubernetes に Falco を展開してアプリケーションの挙動をモニタリングする ? makocchi ? Medium
k8sのaudit logをモニタリング
- k8s APIサーバに対する呼び出しを時系列でログに記録することが可能
- K8Sでaudit loggingを有効にする必要がある
- GKEではdefaultで有効
- webhookの設定とpolicyはfalcoのrepositoryにサンプルが用意されている
- audit policyはrbacに近い設定で定義可能
- audit logを元にrbacのmanifestを自動生成してくれるツールも存在する
インストール
- docker runでもOK
- Helmのchartがあるのでそれが楽
KubeCon + CloudNativeCon 2018 NA Recap Vitess
- Yutaka Ichikawa @cyberblack28 (APC)
- KubeCon + CloudNativeCon 2018 NA Recap Vitess – Speaker Deck
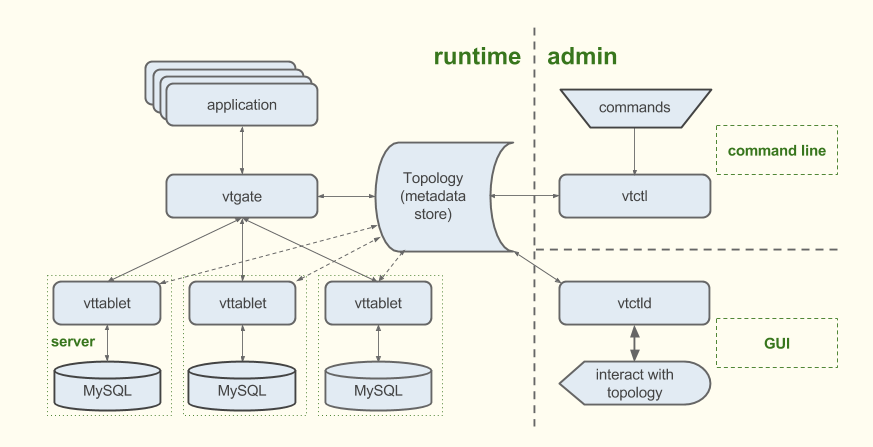
サマリ
- MySQL cloud-native nirvana
- MySQL基盤は複雑
- MySQLクラウドネイティブ解脱への道のり
- k8sでMySQLの管理
Vitess
- MySQLをシャーディングによってスケールを実現するクラウドネイティブなデータベースクラスタシステム
- Youtubeにより開発、Go製
- Slackが20%がVitessへ移行中
- jd.com: 10,000+テーブル on k8s
- アーキテクチャ
- vttabletがサイドカー。クエリの置換、重複除去など
- vtgate: アプリからのクエリをvttabletにルーティング、結果をクライアントへ返すプロキシ
- Vitessシャーディング
- 垂直: テーブルごとに複数データベースに分けて格納
- 水平: 1つのテーブルを複数
- k8sとの相性が良い
事例
- HubSpot: インバウンドマーケティングの統合サービスアプリケーションおよびサービス
- AWS (EC2 * 2500規模) → GCP (k8s + Vitess)
- 選定理由
- シャーディング機能
- k8sとの親和性
- OSS
- クラウドネイティブ
まとめ
- YouTubeの実績は強い
- プロダクション利用が徐々に増えている
- k8sとの親和性が高い
- 設計・運用のチューニングは必要
- マネージドサービスとしてVitess as a Serviceなるものが生まれそう!?
Prometheusの今後
- Yoshi Shota @yosshi_ (NTT Communications)
- Prometheusの今後.pdf – Speaker Deck

Prometheusの課題
- 長期保管の機能がない
- 保管機能を延ばすと性能の劣化がある
デフォルトで冗長機能がない
長期保管: Third party adapterの利用
- Cortex
- M3DB: Uber製
- Thanos/Cortex/M3
Thanos
- 複数のPrometheusを横断してメトリクスの収集を可能にする
- 無制限にログを保管する
上記を応答時間を犠牲にすることなく実現
Querier
- Querier がSIdecar経由でPrometheusから時系列データを取得
- Sidecar → Object Storage
- Store
- Compactor: 圧縮とダウンサンプリングを行う
Ruler: 通知用
2019年1月時点ではGCSのみ対応
Loki
- ログの収集と可視化ツール
- メトリクスだけではインシデントの全容の半分しかわからない
- メトリクスとログの参照時の切替コストを最小限に抑える
- Prometheusを参考にラベルを活用した時系列にデータを格納
- アーキテクチャはCortexと同じ
- ソースコードもCortexを使いまわし…
- まだAlpha版
監視の目指すとこ
- Alert → Dashboard → Adhoc Query → Log Aggregation → Distribute Tracing